 “阿爾法狗”Zero跳出圍棋 多領(lǐng)域挑戰(zhàn)人類
“阿爾法狗”Zero跳出圍棋 多領(lǐng)域挑戰(zhàn)人類“阿爾法狗”Zero跳出圍棋 多領(lǐng)域挑戰(zhàn)人類
近日,DeepMind在arXiv發(fā)表論文表示,AlphaGo Zero已開始嘗試完成其他任務(wù),其現(xiàn)已具有通用性。

DeepMind團(tuán)隊(duì)目前一直以推動人工智能的界限,開發(fā)可以學(xué)會解決任何復(fù)雜問題而不需要學(xué)習(xí)的程序?yàn)樽陨硎姑T诮衲昴瓿酰湟呀?jīng)引入了一種“強(qiáng)化學(xué)習(xí)”(reinforcement learning)的AI技術(shù)來增強(qiáng)AlphaGo,這個技術(shù)不需要人類輸入信息,只需要制定規(guī)則,它就可以自己獲得超人一般的技法。
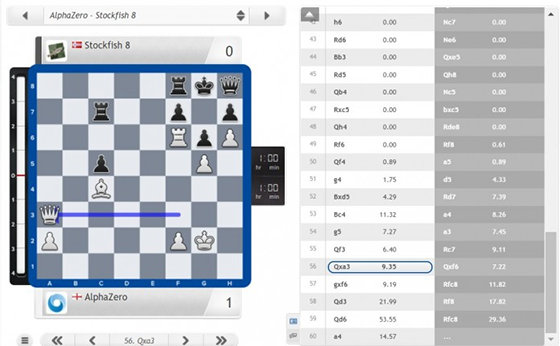
DeepMind舉了兩個例子,表示AlphaGo Zero可以自己學(xué)習(xí)國際象棋和將棋,只需要24小時,它就可以達(dá)到擊敗世界冠軍的水平。(這兩個游戲相比較圍棋而言,較為簡單)
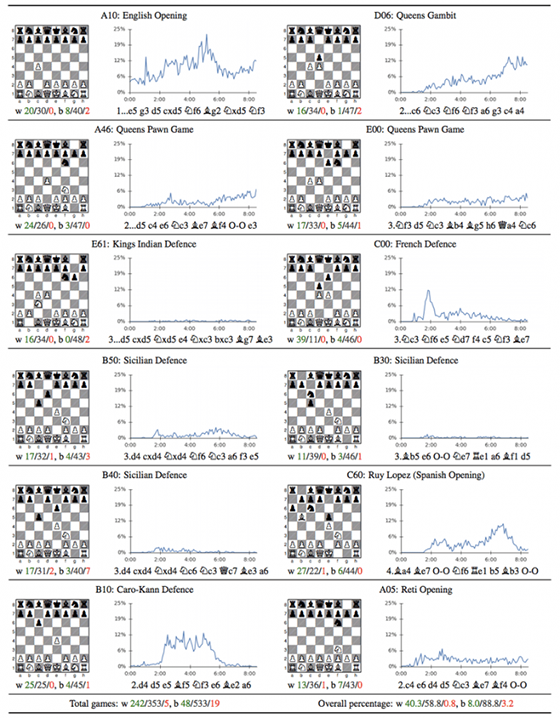
AlphaGo Zero的通用性可使其掌管各種不同的游戲,這無疑是可以讓機(jī)器學(xué)習(xí)能力越來越強(qiáng),但是目前其還無法在策略性游戲(如星際爭霸)超過人類,但是相信以其恐怖的學(xué)習(xí)能力那一天也不會太遙遠(yuǎn)。
點(diǎn)個贊775



熱點(diǎn)資訊
 方永飛公開怒懟小米雷軍:還要不要一點(diǎn)臉,吹牛界祖師爺!二楠3 天前
方永飛公開怒懟小米雷軍:還要不要一點(diǎn)臉,吹牛界祖師爺!二楠3 天前 iPhone 18 Pro外觀大變,沒了靈動島,但看了想讓人吐槽! 二楠5 天前
iPhone 18 Pro外觀大變,沒了靈動島,但看了想讓人吐槽! 二楠5 天前 3090億參量硬剛Deepseek?小米發(fā)布MiMo大模型姜維5 天前
3090億參量硬剛Deepseek?小米發(fā)布MiMo大模型姜維5 天前 爆料稱10080mAh大電池手機(jī)春節(jié)前登場,預(yù)計為榮耀Power 2拖把6 天前
爆料稱10080mAh大電池手機(jī)春節(jié)前登場,預(yù)計為榮耀Power 2拖把6 天前 小米平板已漲價!榮耀高管:實(shí)在扛不住了,我們漲價也快到了!二楠6 天前
小米平板已漲價!榮耀高管:實(shí)在扛不住了,我們漲價也快到了!二楠6 天前 跳過iPhone 19,曝蘋果計劃直接發(fā)布iPhone 20,采用四曲面屏無挖孔設(shè)計Viking上周
跳過iPhone 19,曝蘋果計劃直接發(fā)布iPhone 20,采用四曲面屏無挖孔設(shè)計Viking上周 因沒有創(chuàng)新,媒體怒噴三星Galaxy S26:2026年最差的手機(jī)拖把6 天前
因沒有創(chuàng)新,媒體怒噴三星Galaxy S26:2026年最差的手機(jī)拖把6 天前 小米17 Ultra或啟用雙品牌,徠卡特別版海外命名“Leitzphone”拖把5 天前
小米17 Ultra或啟用雙品牌,徠卡特別版海外命名“Leitzphone”拖把5 天前 ?華為海思芯片排第六,2025年第三季度手機(jī)處理器市場份額出爐Viking4 天前
?華為海思芯片排第六,2025年第三季度手機(jī)處理器市場份額出爐Viking4 天前



 滬公網(wǎng)安備 31010702005758號
滬公網(wǎng)安備 31010702005758號
發(fā)表評論注冊|登錄