 牙膏、馬甲不爭(zhēng)氣 谷歌自研芯片超CPU/GPU15-30倍
牙膏、馬甲不爭(zhēng)氣 谷歌自研芯片超CPU/GPU15-30倍牙膏、馬甲不爭(zhēng)氣 谷歌自研芯片超CPU/GPU15-30倍
谷歌正在自研芯片以加速其機(jī)器學(xué)習(xí)算法,這已經(jīng)不是什么秘密。早在2016年5月的I/O開(kāi)發(fā)者大會(huì)上,谷歌就透露過(guò)這些芯片,稱之為TPU(Tensor Processing Units),但當(dāng)時(shí)除了表明它是圍繞其TensorFlow機(jī)器學(xué)習(xí)框架而設(shè)計(jì)優(yōu)化的產(chǎn)品外,并未公布有關(guān)于這一芯片的更多細(xì)節(jié)。如今,谷歌終于發(fā)布了一些TPU研究的成果。

其實(shí),如果對(duì)這方面感興趣,在谷歌論文(Google's paper)中是可以找到關(guān)于TPU的一些運(yùn)作細(xì)節(jié)的。盡管如此,谷歌自身的基準(zhǔn)測(cè)試結(jié)果,依然聚集了整個(gè)行業(yè)的目光。這一結(jié)果為谷歌評(píng)估自己的芯片,以此為前提,谷歌的公布的情況為:TPU在執(zhí)行谷歌常規(guī)的機(jī)器學(xué)習(xí)工作負(fù)載方面,相較于一個(gè)標(biāo)準(zhǔn)的CPU/GPU組合,Intel Haswell CPU搭配Nvidia K80 GPU,平均要高出15倍至30倍之多。更重要的是,TPU的每瓦特性能(TeraOps/瓦特)達(dá)到了一般CPU/GPU組合的30倍至80倍,如果采用了新的內(nèi)存,這一數(shù)值還將更高。
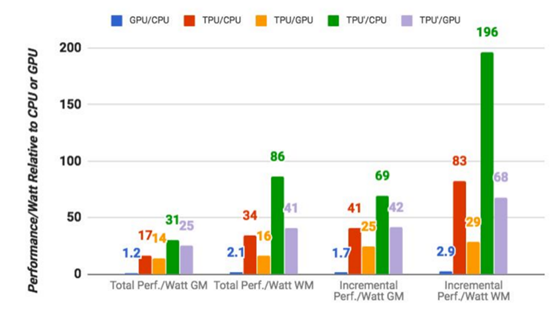
值得注意的是,這些數(shù)字都是關(guān)于生產(chǎn)使用中的機(jī)器學(xué)習(xí)模型,而非新創(chuàng)模型。谷歌還指出,雖然很多構(gòu)架師針對(duì)卷積神經(jīng)網(wǎng)絡(luò)(例如,用于圖像識(shí)別的特定類型神經(jīng)網(wǎng)絡(luò))優(yōu)化了這一芯片,但這些網(wǎng)絡(luò)只占其數(shù)據(jù)中心工作負(fù)載的5%左右,而大部分應(yīng)用程序使用的是多層感知器(multi-layer perceptrons)。這也就意味著,TPU的應(yīng)用場(chǎng)景并不單一,未來(lái)的前景十分廣闊。
谷歌表示,早在2006年,他們就已經(jīng)開(kāi)始研究如何在數(shù)據(jù)中心使用GPU、FPGA和自定義ASIC,這實(shí)際上也是TPU的本質(zhì)。然而,當(dāng)時(shí)并沒(méi)有那么多的應(yīng)用程序真的能受益于這種特殊的硬件,因?yàn)楫?dāng)時(shí)的硬件足夠處理數(shù)據(jù)中心的負(fù)載。谷歌的文章中提到:“在2013年,我們預(yù)計(jì)深度神經(jīng)網(wǎng)絡(luò)(DNN)將會(huì)大有所為,以至于我們數(shù)據(jù)中心的計(jì)算需求將增加一倍,這個(gè)需求如果采用傳統(tǒng)CPU來(lái)解決,將會(huì)異常昂貴。因此,我們開(kāi)始了一個(gè)高度優(yōu)先的項(xiàng)目,以快速生成用于推演的自定義ASIC(并購(gòu)買了現(xiàn)成的GPU來(lái)進(jìn)行訓(xùn)練)。”谷歌的研究人員說(shuō),“這樣做的目的是將GPU的性能提高10倍以上。”
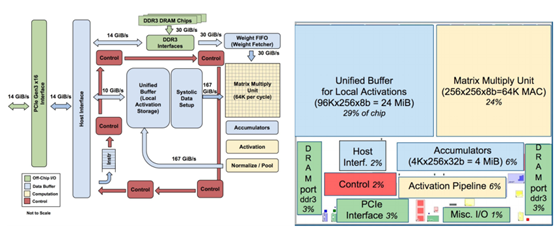
不過(guò),谷歌很有可能并不會(huì)對(duì)外提供TPU。可盡管如此,還是會(huì)有很多人從谷歌的一些設(shè)計(jì)中學(xué)到些東西,得到些靈感,“設(shè)計(jì)出更出色的接班人”也并非不可能。或者至少,能給牙膏廠英特爾、馬甲廠英偉達(dá)帶來(lái)些壓力也是好的。



熱點(diǎn)資訊
 方永飛公開(kāi)怒懟小米雷軍:還要不要一點(diǎn)臉,吹牛界祖師爺!二楠昨天
方永飛公開(kāi)怒懟小米雷軍:還要不要一點(diǎn)臉,吹牛界祖師爺!二楠昨天 iPhone 18 Pro外觀大變,沒(méi)了靈動(dòng)島,但看了想讓人吐槽! 二楠3 天前
iPhone 18 Pro外觀大變,沒(méi)了靈動(dòng)島,但看了想讓人吐槽! 二楠3 天前 等等黨再輸一局!SK海力士稱內(nèi)存供不應(yīng)求將持續(xù)到2028年拖把6 天前
等等黨再輸一局!SK海力士稱內(nèi)存供不應(yīng)求將持續(xù)到2028年拖把6 天前 3090億參量硬剛Deepseek?小米發(fā)布MiMo大模型姜維3 天前
3090億參量硬剛Deepseek?小米發(fā)布MiMo大模型姜維3 天前 爆料稱10080mAh大電池手機(jī)春節(jié)前登場(chǎng),預(yù)計(jì)為榮耀Power 2拖把4 天前
爆料稱10080mAh大電池手機(jī)春節(jié)前登場(chǎng),預(yù)計(jì)為榮耀Power 2拖把4 天前 跳過(guò)iPhone 19,曝蘋果計(jì)劃直接發(fā)布iPhone 20,采用四曲面屏無(wú)挖孔設(shè)計(jì)Viking5 天前
跳過(guò)iPhone 19,曝蘋果計(jì)劃直接發(fā)布iPhone 20,采用四曲面屏無(wú)挖孔設(shè)計(jì)Viking5 天前 小米平板已漲價(jià)!榮耀高管:實(shí)在扛不住了,我們漲價(jià)也快到了!二楠4 天前
小米平板已漲價(jià)!榮耀高管:實(shí)在扛不住了,我們漲價(jià)也快到了!二楠4 天前 小米17 Ultra或啟用雙品牌,徠卡特別版海外命名“Leitzphone”拖把3 天前
小米17 Ultra或啟用雙品牌,徠卡特別版海外命名“Leitzphone”拖把3 天前 因沒(méi)有創(chuàng)新,媒體怒噴三星Galaxy S26:2026年最差的手機(jī)拖把4 天前
因沒(méi)有創(chuàng)新,媒體怒噴三星Galaxy S26:2026年最差的手機(jī)拖把4 天前



 滬公網(wǎng)安備 31010702005758號(hào)
滬公網(wǎng)安備 31010702005758號(hào)
發(fā)表評(píng)論注冊(cè)|登錄